200813 DB분석 실무 과정 2일차
6장. 자유자재로 데이터 가공하기
###6장 데이터 가공하기
install.packages("dplyr") #한번만 설치하면 됨
library(dplyr) #로드는 창을 새로 쓸때마다 해야함
exam<- read.csv("csv_exam.csv")

*dplyr: 데이터 전처리 작업에 가장 많이 사용되는 패키지
함수
-filter(): 행 추출
-select(): 열(변수) 추출
-arrange(): 정렬
-mutate(): 변수추가
...


- 이와 같이 filter함수 내에는 조건식이면 됨

%in%과 c함수를 사용하면 더 간략하게 코드를 표현할 수 있다.
p. 133 혼자서 해보기
mpg데이터를 이용해 분석문제를 해결해 보세요.
Q1) 자동차 배기량에 따라 고속도로 연비가 다른지 알아보려고 합니다. displ(배기량)이 4이하인 자동차와 5이상인 자동차 중 어떤 자동차의 hwy(고속도로 연비)가 평균적으로 더 높은지 알아보세요.
Q2) 자동차 제조회사에 따라 도시연비가 다른지 알아보려고 합니다. "audi"와 "toyota" 중 어느 manufacturer(자동차 제조회사)의 cty(도시연비)가 평균적으로 더 높은지 알아보세요.
Q3) "chevrolet","ford","honda" 자동차의 고속도로 연비 평균을 알아보려고 합니다. 이 회사들의 데이터를 추출한 후 hwy 전체평균을 구해보세요.

06-3. 필요한 변수만 추출


- 해당변수를 제외할 때는 변수앞에 - 를 사용


-똑같이 , 로 연결하면 여러 변수를 지정할 수 있다.

-여러 함수를 조합해서 사용하려면, 함수가 바뀔 때 마다 파이프(%>%)를 사용

- 파이프 쓸때마다 사용하면 가독성이 좋아짐

head함수를 조합하여 보고싶은 데이터 갯수를 설정할 수도 있다.
p.138 혼자서 해보기
mpg 데이터를 이용해 분석 문제를 해결해 보세요.
Q1) mpg데이터는 11개 변수로 구성되어 있습니다. 이 중 일부만 추출해 분석에 활용하려고 합니다.
mpg 데이터에서 class(자동차 분류), cty(도시연비) 변수를 추출해 새로운 데이터를 만드세요. 새로 만든 데이터의 일부를 출력해 두 변수로만 구성되어 있는지 확인하세요.

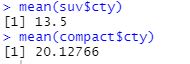
Q2) 자동차 종류에 따라 도시 연비가 다른지 알아보려고 합니다. 앞에서 추출한 데이터를 이용해 class(자동차 종류)가 "suv"인 자동차와 "compact"인 자동차 중 어떤 자동차의 cty(도시연비) 평균이 더 높은지 알아보세요.

06-4. 순서대로 정렬하기
arrange(): 정렬 함수


06-5. 파생변수 추가하기

- exam 데이터 자체가 변경된 것은 아님 !

-변수를 여러개 추가하고 싶다면 ,(콤마)로 구분

- 조건에 따라 다른 값 ifelse()를 적용할 수 있다.
p.144 혼자서 해보기
mpg데이터를 이용해 분석 문제를 해결해 보세요.
mpg데이터는 연비를 나타내는 변수가 hwy(고속도로 연비), cty(도시 연비) 두 종류로 분리되어 있습니다. 두 변수를 각각 활용하는 대신 하나의 통합 연비 변수를 만들어 분석하려고 합니다.
Q1) mpg() 데이터 복사본을 만들고, cty와 hwy를 더한 '합산 연비 변수'를 추가하세요.

Q2) 앞에서 만든 '합산 연비 변수'를 2로 나눠 '평균 연비 변수'를 추가하세요.

Q3) '평균 연비 변수'가 가장 높은 자동차 3종의 데이터를 출력하세요.

Q4) 1~3번 문제를 해결할 수 있는 하나로 연결된 dplyr 구문을 만들어 실행해보세요. 데이터는 복사본 대신 mpg원본을 사용하세요.

06-6. 집단별로 요약하기
group_by(), summarise()

- class를 기준으로 그룹화
- 수학점수의 평균,합계,중간값,빈도수를 구함

p.150 혼자서 해보기




06-7 데이터 합치기
*가로로 합치기

-당연히 right_join도 있음, 기준이 되는 데이터가 달라짐
*세로로 합치기

-혼자서 해보기 pass
7장. 데이터 정제- 빠진 데이터, 이상한 데이터 제거하기
07-1. 빠진 데이터를 찾아라!- 결측치 정제하기
* 결측치(Missing Value)
- 누락된 값, 비어있는 값
- NA로 표시된 값
*결측치 찾기

한 변수로 줄이기
=> table(is.na(df$sex))
=>점수의 평균을 구하고싶음

-score에 결측값이 포함되어 계산 값이 나타나지 않음

- score변수의 결측지만 제거하여 df_nomiss에 저장
- df_nomiss의 score변수의 중간값을 구함 =>4
=> 그렇다면, 하나의 칼럼이 아닌 전체 데이터프레임에 결측치를 모두 제거하려면?

-두가지 방법이 있음


- exam데이터에 3,8,15번째 math데이터에 NA(결측값)을 넣어라

* 결측치 대체하기
- 결측치 많을 경우 모두 제외하면 손실이 큼
- 결측치를 나머지들의 평균값으로 대체함

-exam 테이블의 math칼럼에서 결측값을 제외한 평균값을 구함 => 55.23529
- exam의 math칼럼에 결측값이면 평균값인 55를 넣고, 아니라면 원래 값을 다시 넣어줌
p.170 혼자서 해보기
mpg원본에는 결측치가 없습니다. 우선 mpg데이터를 불러와 일부러 몇 개의 값을 결측치로 만들겠습니다. 아래 코드를 실행하면 다섯 행의 hwy변수에 NA가 할당됩니다.
Q1) drv(구동방식)별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 합니다. 분석을 하기 전에 우선 두 변수에 결측치가 있는지 확인해보자.

Q2) filter()을 이용해 hwy변수의 결측치를 제외하고 어떤 구동방식의 hwy평균이 높은지 알아보세요.
하나의 dplyr 구문으로 만들어야 한다.

07-2. 이상한 데이터를 찾아라!- 이상치 정제하기
*이상치(Outlier)
: 정상 범주에서 크게 벗어난 값


* 극단적인 값일때

위에 극단적인 값이 두개정도 있는 것으로 보임, 그리고 선은 38정도 (35-40사이)
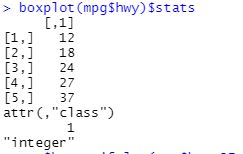
- 맨윗줄 값이 37인 것을 확인함
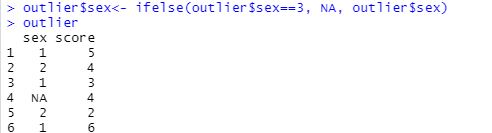
=> 37이 넘어가면 NA로 바꾸기


=> 극단적인 값이 두개인것 같아 보였는데 갯수를 내보니 3개임
=> 너무 그래프만 보고 의존하지 X
8장. 그래프 만들기
네이버 검색어 트렌드
-해당 검색어의 추세를 나타내줌
-광고를 언제할지, 결정하는데 사용할 수 있음
08-2. 산점도- 변수 간 관계 표현하기

1. 배경설정하기
- data: 그래프를 그리는 데 사용할 데이터를 지정
- aes: x축과 y축에 사용할 변수를 지정하면 배경이 만들어진다.
- geom_point(): 산점도 (그래프 종류)
- xlim(3,6): x축 범위 3~6으로 설정
- ylim(10,30): y축 범위 10~30으로 설정

p.188 혼자서 해보기

08-3. 막대 그래프- 집단 간 차이 표현하기
geom_col(): 데이터를 요약한 평균표를 먼저 만든 후 평균표를 이용해 그래프 생성 (평균 막대 그래프)
geom_bar(): 별도로 표를 만들지 않고 원자료를 이용해 바로 그래프 생성 (빈도 막대 그래프)
08-4. 선그래프- 시간에 따라 달라지는 데이터 표현하기
ggplot(data= economics, aes(x= date, y= unemploy))+ geom_line()

08-5. 상자그림- 집단 간 분포 차이 표현하기

ggplot(data= mpg, aes(x= drv, y=hwy))+ geom_boxplot()
9장. 데이터 분석 프로젝트
*데이터 분석 절차
1. 변수 검토
class(), table()
2. 전처리
table(is.na()), ifelse, summary() 를 통해 이상치-> 결측치
3. dplyr패키지 활용
4. 그래프 그리기
------------------------------------------------------------------------------------------------------------------------


학교에서 너무 잘해주는 거 아니냐며,,,
2일동안 오전부터 학교에 계속 교육듣고, 틈틈이 많은양의 토익학원 숙제를 또하구 밤9시까지 학원 수업을 듣는게
너무 힘들고 내일도 해야하지만 3일만 하면 된다는 생각으로 열심히 하는중!
밥이라도 무료로 잘 챙겨줘서 너무조타~~!
이왕 듣는 거 알뜰히 열심히 잘 듣고 뭐라도 남는게 잇기를 !